 |
| ||||||||||
2.3.7: Der AQ-Algorithmus
Unter dem Namen AQ-Algorithmus werden eine ganze Reihe Verfahren zusammengefasst, die für verschiedene Probleme entwickelt wurden. Einführungen finden sich in Michalski (1983) [->] und Michalski, Mozetic, Hong und Lavrac (1986) [->] . Hier soll der auch in Holsheimer und Siebes (1994) [->] dargestellte AQ15-Algorithmus in einer einfachen Form vorgestellt werden. Der AQ15-Algorithmus generiert IF-THEN-Regeln, die Kategorien beschreiben.
 Definition 15: Selektor, Komplex, Abdeckung
Definition 15: Selektor, Komplex, Abdeckung
Für jede Kategorie in einer konsistenten Beispielsammlung kann man eine Abdeckung finden, die die Kategorie beschreibt. Dazu schreibt man, wie oben im formalen Algorithmus beschrieben, die Tupel aus einer Kategorie als Konjunktionen ihrer Attribut-Wert-Paare und bildet über diese (sehr einfachen) Komplexe eine Disjunktion. Diese Beschreibung durch Aufzählung ist aber natürlich nicht sehr nützlich. Es müssen also einfachere Beschreibungen gefunden werden.
Abbildung 60: Verallgemeinerung von Regeln
Dazu führt AQ15 eine heuristische Suche im Raum aller Abdeckungen durch, um diejenigen zu finden, die genau die Beispiele einer Kategorie beschreiben und keine anderen Beispiele der Trainingsmenge. Dabei können von Nutzenden Präferenzkriterien angegeben werden, die bei mehreren passenden Regeln die bevorzugte auswählen. Solche Präferenzkriterien können z.B. die Anzahl der Selektoren in einem Komplex oder auch spezifische Kostenfunktionen für einzelne Selektoren sein. Die Suche im Raum der Abdeckungen wird konstruktiv durch Operationen, die generalisieren, und solche, die spezialisieren, durchgeführt. In einem einfachen Fall kann man dazu die folgenden Operationen verwenden:
- Hinzufügen von erlaubten Werten zu einem Selektor (Generalisierung)
- Hinzufügen eines Komplexes zu einer untersuchten Abdeckung (Generalisierung)
- Schneiden eines Komplexes mit einem weiteren Selektor (Spezialisierung)
Das zentrale Konstrukt des Algorithmus ist das des Sterns (star):
Definition 16: Stern
Im Folgenden werden Sterne häufig innerhalb der
Elemente einer Kategorie X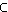 D
berechnet. Das heißt, man setzt
Y=D\X
und die zweite Bedingung geht in die
äquivalente Bedingung KX
über.
Der Algorithmus zum Lernen einer einzelnen Kategorie XD
aus einer Menge von Beispielen D
kann folgendermaßen geschrieben werden:
D
berechnet. Das heißt, man setzt
Y=D\X
und die zweite Bedingung geht in die
äquivalente Bedingung KX
über.
Der Algorithmus zum Lernen einer einzelnen Kategorie XD
aus einer Menge von Beispielen D
kann folgendermaßen geschrieben werden:
Algorithmus 6: AQ15: Regelgenerierung
Ein maximaler Komplex eines Beispiels d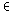 D
in
X
ist ein Komplex
KX
, für den gilt:
Falls ein Komplex Q
D
in
X
ist ein Komplex
KX
, für den gilt:
Falls ein Komplex Q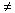 K
mit
KQ
existiert, folgt
Q⊄X
. Ein Element kann mehrere maximale Komplexe
haben (zwischen denen keine Teilmengenrelation herrschen kann).
K
mit
KQ
existiert, folgt
Q⊄X
. Ein Element kann mehrere maximale Komplexe
haben (zwischen denen keine Teilmengenrelation herrschen kann).
Abbildung 61: Beispiele nach Kategorien sortiert
Um eine Annäherung an die maximalen Komplexe eines Elements
dX
in einer Kategorie X
zu berechnen, verwendet man in Schritt 2 einen
beschränkten partiellen Stern für ein positives Beispiel
d
aus
X
.
Algorithmus 7: AQ15: Partieller Stern
Die mit dem Algorithmus gefundene Abdeckung C kann durch weitere Generalisierungen optimiert werden. Bei der Berechnung des beschränkten Sterns handelt es sich um ein Beam-Search-Verfahren, da eine ganze Liste von Komplexen verwaltet wird.
Abbildung 62: Konstruktion einer Abdeckung
Die Abbildung
62
zeigt die Anwendung des AQ15-Algorithmus
auf die Beispiele aus Abbildung 61
.
Zunächst wird ein Beispiel
d=(0,1,0,0)
aus der zu beschreibenden Kategorie gewählt und
dazu der partielle Stern berechnet. Dabei wurden die Beispiele
r(D\X)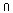 K
j
,
j{1,...,k}
so gewählt, dass sie sich in möglichst
wenigen Attributen von dem Beispiel
d
unterscheiden. Dadurch wird die Anzahl der maximalen
Komplexe klein gehalten und das Beispiel überschaubar. Es
können natürlich auch andere Auswahlkriterien angewendet
werden.
K
j
,
j{1,...,k}
so gewählt, dass sie sich in möglichst
wenigen Attributen von dem Beispiel
d
unterscheiden. Dadurch wird die Anzahl der maximalen
Komplexe klein gehalten und das Beispiel überschaubar. Es
können natürlich auch andere Auswahlkriterien angewendet
werden.
Die Beschränkung des partiellen Sterns auf eine feste Anzahl von Komplexen wurde nicht verwendet (d.h., die zulässige Anzahl an Komplexen wurde so groß gewählt, dass sie nicht erreicht wurde). Dadurch werden alle Komplexe mitgeführt.
Beim ersten Beispiel d=(0,1,0,0) zeigt sich der Einfluss der Auswahl des Komplexes, der in die Abdeckung übernommen wird. Wäre statt des Komplexes mit dem Selektor (A3=0) der andere Komplex mit (A4=0) gewählt worden, wäre das zweite Beispiel d=(0,1,1,0) bereits mit abgedeckt gewesen. Eine Regel, die eine solche Wahl bewirkt hätte, wäre z.B. solche Komplexe zu wählen, die möglichst viele positive Beispiele abdecken.
Beim dritten Beispiel
d=(1,1,0,1)
aus der Kategorie wurde mit
r=(0,0,0,1)(
D\X)Kj
zunächst ein Beispiel gewählt, das sich in
vielen Attributen von
d
unterscheidet. Dadurch ergeben sich erheblich mehr
Komplexe.
Im zweiten Block von Abbildung 62
sind
zunächst alle Schnittmengen aufgeführt. Man sieht aber, dass
eine ganze Reihe davon doppelt auftreten. Nach dem zweiten P sind die
doppelten Komplexe weggelassen.
Weiter sieht man, dass bei der Durchschnittsbildung Komplexe entstehen, die Teilkomplexe von anderen Komplexen sind. Hier könnte man im Sinne einer maximalen Generalisierung die Teilmengen weglassen. Die einzige Forderung an den partiellen Stern, die dabei immer erfüllt sein muss, ist, dass er d enthalten muss und r nicht enthalten darf. Darüber hinaus können Operationen und Auswahlregeln angewendet werden, die sinnvoll erscheinen, um das Verfahren zu vereinfachen und zu beschleunigen. So könnte man wieder vor allem solche Komplexe übernehmen, die möglichst viele Beispiele aus der zu beschreibenden Kategorie enthalten, und möglichst wenige, die nicht in diese Kategorie fallen. So könnte man, im Gegensatz zur oben vorgeschlagenen Verallgemeinerung, solche Komplexe weglassen, die Obermengen von anderen Komplexen sind und noch Gegenbeispiele enthalten, während die Untermengen ganz in der Kategorie liegen. So ist im letzten Block von Abbildung 62 (A1=1)&(A4=1) Obermenge von (A1=1)&(A3=0)&(A4=1). Der erste Komplex enthält aber mit (1,0,1,1) noch ein Beispiel, das nicht in der zu beschreibenden Kategorie liegt, der zweite enthält dagegen keines mehr. In diesem Fall ist es klar, dass der erste Komplex zu Gunsten des zweiten weggelassen werden kann. Wenn es aber verschiedenen Spezialisierungen gäbe, die alle zwar weniger, aber doch immer Beispiele enthalten, die nicht in der Kategorie liegen, wäre es nicht so eindeutig, welche Spezialisierung günstiger ist.
In diesem Beispiel enthält die Beispielmenge einen großen Teil der möglichen Tupel. In vielen praktischen Fällen tritt nur ein vergleichsweise kleiner Teil der möglichen Tupel auch tatsächlich in der Trainingsmenge auf. Sind die Wertebereiche der Attribute z.B. die reellen Zahlen oder reelle Intervalle, so schneidet die Konstruktion über maximale Komplexe nur jeweils die Punkte der Gegenbeispiele heraus. Es ist aber z.B. bei Ergebnissen physikalischer Experimente oder bei medizinischen Tests sehr unwahrscheinlich, dass nur die exakten Werte der Beispiele aus der Kategorie herausfallen. Viel wahrscheinlicher ist, dass ganze Intervalle entfernt werden müssten, für die ein Gegenbeispiel jeweils nur ein Prototyp ist. In diesen Fällen kann es sinnvoll sein, neben den hier betrachteten Spezialisierungen auch Generalisierungen zu verwenden.
2.3.7.1: Generalisierungsoperationen
| Navigation | [ Zurück ] [ Inhalt ] [ Stichwörter ] [ Feedback ] [ Home ] |
| Position im Angebot | Information Retrieval -> Wissensgewinnung mit Data-Mining-Methoden -> Kategorisieren |