2.4.2: Unscharfe Mengen
Während in Cluster-Verfahren Teilmengen von
ähnlichen Beispielen konstruiert werden, kann man auch versuchen,
die Definition von Mengen so zu verallgemeinern, dass vage Zuordnungen
von Beispielen in unterschiedliche Teilmengen besser abgebildet werden
können. Dazu wurden bereits 1965 von L. A. Zadeh [->]
so genannte unscharfe Mengen oder Fuzzy Sets eingeführt.
Die folgende Darstellung orientiert sich an Bademer und
Gottwald (1993) [->]
.
Die Theorie der unscharfen Mengen stellt als eine
Verallgemeinerung des Mengenkonzepts den
Grad der Mitgliedschaft in einer Menge zur Verfügung.
Diese Verallgemeinerung wird mit Hilfe einer Zugehörigkeitsfunktion definiert:
Bei unscharfen Mengen muss für ein Element also
nicht mehr eindeutig gesagt oder bestimmt werden, ob es in einer
bestimmten Menge liegt oder nicht, sondern es kann ein
Zahlenwert zwischen 0 und 1
angegeben werden, der die Zugehörigkeit
des Elements zu
der Menge
beschreibt. Das entspricht der Gewichtung
von Termen in der Vektordarstellung eines Dokuments.
Dort war allerdings keine Einschränkung der Werte auf
das Intervall
[0,1]
festgelegt worden. Eine solche
Einschränkung kann allerdings im Allgemeinen durch eine geeignete
Normierung erreicht werden. Dabei müssen aber die Auswirkungen auf
die verwendeten Ähnlichkeitsmaße berücksichtigt werden.
Im Unterschied zum Vektorraummodell ist die Definition von
unscharfen Mengen nicht auf eine endliche (Grund-)Menge von Termen
beschränkt. Sie wurde für beliebige Mengen eingeführt.
In Abbildung 66
sind verschiedene Lebensabschnitte als
unscharfe Mengen über dem Grundraum der Lebensjahre dargestellt.
Die herkömmliche Mengendefinition (oder die
Definition einer scharfen Menge) lässt sich als
Spezialfall der Definition
einer unscharfen Menge schreiben. Dazu
wählt man als Zugehörigkeitsfunktion einer Menge
U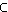 D
die
charakteristische Funktion: D
die
charakteristische Funktion:
| mU |
(d) |
=
1U |
(d) |
=
|
{ |
| 1 |
falls d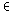 U U |
|
0 |
sonst |
|
Das ist das gleiche Vorgehen wie bei
der Beschreibung des booleschen Retrieval als Spezialfall des
Vektorraummodells.
Zwei unscharfe Mengen sind genau dann gleich,
wenn ihre Zugehörigkeitsfunktionen
gleich sind. Die leere unscharfe Menge
ist durch die Zugehörigkeitsfunktion
mØ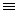 0 0
|
gegeben, die Grundmenge
D
durch
|
mD1
|
Weiter können folgende Begriffe definiert werden:
Bei endlichen Grundmengen, wie sie beispielsweise im Vektorraummodell auftreten,
kann man das Supremum durch das Maximum ersetzen.
Zur weiteren Untersuchung der Eigenschaften unscharfer Mengen bzw.
zur weiteren Verallgemeinerung von Eigenschaften scharfer Mengen auf
unscharfe Mengen kann man die folgende Aussage benutzen, die eine
Beziehung zwischen scharfen und unscharfen Mengen herstellt.
Das lässt sich folgendermaßen
einsehen:
1X>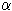 ist die charakteristische Funktion des
-Schnitts. Sie ist also so lange gleich
1
, wie
d
in
X>
liegt. Das ist aber genau dann der Fall, wenn
mX(d)>
gilt. Mit wachsendem
ergibt sich das Supremum also gerade für
=mX(d)
ist die charakteristische Funktion des
-Schnitts. Sie ist also so lange gleich
1
, wie
d
in
X>
liegt. Das ist aber genau dann der Fall, wenn
mX(d)>
gilt. Mit wachsendem
ergibt sich das Supremum also gerade für
=mX(d)
Mit dieser Äquivalenz lassen sich Eigenschaften
und Operationen von scharfen auf unscharfe Mengen
übertragen. Geht man von der Teilmengenrelation für
scharfe Mengen aus, kann man fordern, dass die
-Schnitte einer Teilmengenrelation unscharfer
Mengen die Teilmengenrelation für
scharfe Schnitte erfüllen sollen. Man
erhält als Definition also
Aus der rechten Seite kann man eine äquivalente
Bedingung für die Zugehörigkeitsfunktionen ableiten:
Für ein beliebiges
dD
setzt man
=mY(d)
. Dann folgt aus
dY>=
, dass auch
dX>=
gilt und damit
mX(d)>=
, also
mX(d)>=mY
(d) 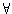 d
D
. Umgekehrt folgt aus
mX(d)>=mY
(d) d
D
nach der Definition des Schnitts
X>= d
D
. Umgekehrt folgt aus
mX(d)>=mY
(d) d
D
nach der Definition des Schnitts
X>=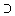 Y>=
. Zusammen gilt also Y>=
. Zusammen gilt also
Man kann also die Teilmengenrelation für unscharfe Mengen
durch diese Äquivalenz definieren.
Für sie folgt dann unmittelbar:
|
ØXD
|
sowie
Wie bei den scharfen Mengen gibt es auch bei
unscharfen Mengen verschiedene sinnvolle Maße
für die Größe einer Menge, je nachdem, ob
der Träger endlich, abzählbar oder messbar ist.
Bei endlichem Träger kann man analog zur
Anzahl der Elemente einer scharfen Menge die Summe der Werte der
Zugehörigkeitsfunktion verwenden.
|
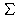 |
| dsupp(X)
|
|
mX |
(d) |
Bei abzählbarem Träger kann diese Summe
(anders als bei der scharfen Menge) endlich
sein oder auch nicht. Bei messbarem, aber nicht endlichem
Träger kann man das Integral über die
Zugehörigkeitsfunktion als Maß für die Größe
der Menge verwenden.
|
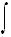 |
| supp(X)
|
|
mX |
(x) |
dx
|
Interessant sind dabei vor
allem relative Größenangaben, also Angaben darüber,
welchen Anteil der Größe der Grundmenge eine Teilmenge
einnimmt. Diese relativen Größenangaben können
für die verschiedenen Größenmaße berechnet
werden.
Man sieht, dass sich diese Definitionen
bei der
Verwendung von scharfen Mengen, also
von charakteristischen
Funktionen, mit den
herkömmlichen Definitionen
von Vereinigung, Durchschnitt und Komplement
decken.
Aus den entsprechenden Eigenschaften der Maximumsfunktion ergeben
sich auch sofort
- die Kommutativität:
Y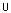 X=XY X=XY
|
- die Assoziativität:
- die Idempotenz:
|
XX=X
|
- und die Monotonie:
Diese Eigenschaften lassen sich auch für den Durchschnitt
zeigen. Entsprechend lassen sich auch Distributivgesetze und
die Regeln über den Zusammenhang von Vereinigung und Durchschnitt mit der Komplementbildung
(Regeln von de Morgan) auf unscharfe Mengen übertragen.
Schließlich gilt
und
Neben dieser "kanonischen" Definition von Vereinigung
und Durchschnittsbildung gibt es noch weitere Möglichkeiten, solche
Operationen zu definieren. Darauf soll hier nicht eingegangen werden.
Es soll aber noch angedeutet werden, wie
Fuzzy-Methoden zum unscharfen Schließen
bzw. unscharfen Kategorisieren verwendet werden können.
Dazu kann man
unscharfe Relationen analog zu
scharfen Relationen als Teilmengen der entsprechenden kartesischen
Produkte definieren:
Eine (scharfe) Relation zwischen zwei
Attributen A1:D->R1
und
A2:D->R2
kann als Teilmenge des kartesischen Produkts der
Wertemenge der Attribute geschrieben werden.
|
TR1×R2={(
x,y) | xR1,yR
2}
|
Die Gleichheit zweier
Attribute kann damit z.B. als Relation der Form
geschrieben werden.
Kategorisierungsregeln, wie sie z.B. beim
AQ-Algorithmus beschrieben wurden, können auch als
Relationen dargestellt werden. Die folgende Darstellung beschränkt sich der Einfachheit
halber auf Kategorisierungen, die durch ein vorherzusagendes Attribut
A2
beschrieben sind
und sich nur auf ein
vorhersagendes
Attribut A1
stützen.
Wie beschrieben, lässt sich jede Kategorisierung durch die geeignete Wahl
bzw. Konstruktion von A1
auf
diese Aufgabe reduzieren. Sie ist
dann eine Funktion, die sich als Regel in der Form
IF
(A1=x)
THEN
A2=y
schreiben
lässt und als Relation in der Form
Die charakteristische Funktion der Gleichheitsrelation auf der
Menge der Paare ergibt sich z.B. für
R=R1=R2={0,1,2}
in der Form:
Ein Eintrag
ti,j
in dieser Matrix gibt an, ob der Wert
xi
der Variablen x
und
der Wert yj
der
Variablen y
die Relation
erfüllen (1) oder nicht (0).
Schreibt man ein Element aus R
auch als seine charakteristische
Funktion, also z.B. 1R
als
x=(0,1,0)t
, so ergibt sich die
Kategorisierung als Multiplikation der Matrix
T
mit dem
Vektor x
.
Man kann sie in der Form
IF
(A1=x)
THEN
A2=T·x
schreiben oder einfacher als
In dieser Weise werden Kategorisierungen
beschrieben, solange die Matrix eine
Permutationsmatrix ist, solange also in jeder Zeile und in
jeder Spalte genau eine 1
steht. Allgemeiner kann man die
IF-THEN-Regel als eine Verknüpfung der
charakteristischen Funktion des Werts von
A1
mit der Relation
betrachten.
Die Darstellung der Relation durch die
charakteristische Funktion ermöglicht die
Verallgemeinerung der Relation zu einer unscharfen
Relation und damit die
Definition einer unscharfen Kategorisierung.
Während bei der
scharfen Relation nur
0
und
1
als Beschreibungen der Zugehörigkeit
zur Teilmenge der Paare zulässig sind, sind bei der unscharfen Relation
Zugehörigkeiten aus dem Intervall
[0,1]
erlaubt, z.B.:
Eine unscharfe IF-THEN-Regel kann nun mit Hilfe einer unscharfen Relation
folgendermaßen geschrieben
werden: IF
(A1=X)
THEN
A2=Y
mit unscharfen Mengen X
und Y
.
Die Zugehörigkeitsfunktion von Y
ist dabei folgendermaßen definiert:
| mY |
(y) |
= |
|
| sup |
| xR1 |
|
{min
(mX(x)
,mT(x,y))
} |
yR2 |
Dabei werden x
und y
wie die Indices der Matrixelemente gelesen.
Diese von Zadeh vorgeschlagene Definition lehnt sich an das Produkt
zwischen dem Vektor und der Matrix an. Die Multiplikation wird dabei durch das Minimum
ersetzt und die Addition durch die
Supremumsbildung. Das Ergebnis dieser unscharfen Kategorisierung ist eine
unscharfe Menge, also eine Zugehörigkeitsfunktion.
|

 Definition 17: Unscharfe Menge
Definition 17: Unscharfe Menge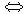 Y>=
Y>=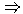 Y=X
Y=X
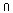 X)>
X)>