3.3.2: Bayessche Inferenznetze
Während beim Imaging die Dokumente nur als Mengen von Termen
behandelt wurden, können bei stärker strukturierten Dokumenten
logische Verfahren besser zum Tragen kommen. Allerdings wird sich auch
hier zeigen, dass die Komplexität, die eine genauere Modellierung
der Struktur eines Dokuments mit sich bringt, der Anwendung für
große Dokumentenmengen immer wieder Grenzen setzt.
Ein bayessches Inferenznetz kann als ein gerichteter Graph definiert
werden, dessen Knoten Aussagen und dessen Kanten Abhängigkeiten zwischen
Aussagen darstellen. Die Knoten können Wahrscheinlichkeitswerte zwischen
0
und
1
annehmen.
Diese Wahrscheinlichkeiten
dienen als Ausgangswerte zur Berechnung neuer Wahrscheinlichkeiten in
den Knoten, auf die die Kanten zeigen. Dazu besitzt jeder Knoten eine Funktion oder Tabelle, die
aus der Wahrscheinlichkeit der Knoten, die auf ihn zeigen, eine neue
Wahrscheinlichkeit berechnet. Im einfachsten Fall, wenn es zu einem Knoten nur einen
anderen Knoten gibt, der auf ihn zeigt, kann das die einfache bedingte
Wahrscheinlichkeit sein.
Zur Informationsverarbeitung geht man nun von einem Muster von
Aktivierungen auf den Knoten des Netzes aus. Aufgrund dieses
Aktivierungsmusters werden für alle Knoten mit den zugehörigen
Funktionen neue Aktivierungswerte berechnet. Dies kann so lange
wiederholt werden, bis sich die so berechneten Muster nicht mehr oder
nur noch minimal unterscheiden. In diesem Fall spricht man von
Konvergenz des Netzes. Sie muss nicht in jedem Fall eintreten.
Zur Anwendung im Information Retrieval führen Turtle und Croft
(1990) [->]
, (1991) [->]
ein zweigeteiltes Inferenznetz
ein. Dabei beschränken sie sich auf einen azyklischen
Graph, der in Schichten organisiert ist. Der eine Teil, das
Dokumentennetz
(document network), besteht
aus drei Schichten von Knoten,
Die Kanten des Netzes können nur zwischen den Schichten
bestehen und nur von Dokumentknoten zu
Textrepräsentationsknoten
und von Textrepräsentationsknoten zu
Konzeptrepräsentationsknoten
führen. Dieser Teil des Netzes wird nur von den Dokumenten einer
Dokumentensammlung bestimmt.
Der zweite Teil des Netzes, das
Anfragenetz
(query network), kann
ebenfalls aus mehreren Schichten bestehen, wobei
die erste Schicht mit der Konzeptrepräsentationsschicht
verbunden ist und die letzte Schicht nur aus einem Knoten besteht,
dessen Wahrscheinlichkeitswert als Wahrscheinlichkeit der mit dem Netz
berechneten Inferenz interpretiert wird. Dieser Teil des Netzes ist nur von der jeweiligen Anfrage
abhängig und nicht von den Dokumenten.
Um mit dem Netz eine Inferenz zu berechnen, werden die
Werte der Dokumente, deren Relevanz zu einer
Anfrage berechnet werden soll, auf den Wert
1
gesetzt, die Knoten der
anderen Dokumente erhalten den Wert
0
. Da
der Graph in Schichten organisiert ist, die Verbindungen im Netz also
nur in eine Richtung verlaufen, muss hier nicht untersucht werden, ob
das Inferenznetz konvergiert. Die Informationsverarbeitung
beschränkt sich darauf, von Schicht zu Schicht neue Aktivierungen
zu berechnen. Es kann also von vornherein bestimmt werden, nach
wie vielen Iterationen die Aktivierung der Eingabeknoten in der letzten
Schicht angekommen ist. Es werden also bei der
Textrepräsentationsschicht beginnend sukzessive
für die Knoten jeder Schicht die
Wahrscheinlichkeitswerte berechnet, bis schließlich
im letzten Knoten des Inferenznetzes die Relevanz
abgelesen wird. Dieser Wert ist eine Funktion
verschiedener Beiträge, die über verschiedene
Pfade durch das Netz propagiert werden. Sie
repräsentieren die verschiedenen Aspekte, die zur
Beurteilung der Wichtigkeit eines Dokuments beitragen.
Die Dokumentenschicht
In der ersten Schicht des Netzes werden die verschiedenen Dokumente
der Sammlung repräsentiert. Um die Dokumente in eine
Rangfolge bezüglich einer Anfrage zu
bringen, werden die Werte der Dokumentknoten einzeln auf 1
gesetzt und der Wahrscheinlichkeitswert der Inferenz
berechnet. Es können aber auch mehrere Knoten auf
1 gesetzt werden, dann wird die Relevanz der entsprechenden
Dokumentenmenge berechnet.
Die Textrepräsentationsschicht
Die Knoten dieser Schicht stehen für verschiedene Textteile, -typen oder
-sichten. Dabei kann ein Dokument mehrere
Textrepräsentationsknoten besitzen. So können z.B.
verschiedene Felder eines Dokuments, wie Titel oder
Abstract oder - bei längeren Dokumenten -
verschiedene Kapitel oder Teile, durch unterschiedliche Knoten
repräsentiert werden. Bei multimedialen
Dokumenten können die verschiedenen Modalitäten wie
Bilder, Audio- oder Videodaten verschiedenen Knoten
zugewiesen werden. Auch Kommentare, Klassifikationen, Indexterme oder
Einschätzungen aus Gutachten oder von anderen Nutzenden können
speziellen Knoten zugeordnet werden.
Die Konzeptrepräsentationsschicht
Die Knoten dieser Schicht repräsentieren
abstrakte Konzepte.
Ihre Aktivierungen werden aus denen der
Textrepräsentationsknoten
berechnet. Sie stellen die Schnittstelle zum Anfragenetz dar.
Die drei Schichten des Dokumentennetzes stellen also eine
zunehmende Abstrahierung der Dokumentinhalte von der
jeweiligen Oberflächenform dar, in der sie in den
Dokumenten vorliegen. Neben der Definition der entsprechenden
Knoten stellt insbesondere die Bestimmung der
Übergangsfunktionen für die Knoten ein Problem
dar. Sie müssen einerseits einfach genug sein,
um auch für große Dokumentensammlungen berechnet werden zu können,
andererseits stellt ihre Flexibilität ein wesentliches Merkmal der
Methode dar.
Das Anfragenetz ist in der Theorie von Turtle und Croft einfacher
strukturiert. Zwischen den Konzepten und dem Bewertungsknoten
sehen sie eine Schicht mit verschiedenen
Anfragetypen vor, die verschiedene Konzepte
zusammenfassen.
Dadurch, dass man die Verarbeitung der Information in einem Netz grafisch
darstellt, lassen sich die verschiedenen Schritte gut
nachvollziehen. Insbesondere die verschiedenen Wege, auf denen
Teile eines Dokuments zur Gesamtgewichtung beitragen können, sind
gut sichtbar. Andererseits ist die vollständige
Modellierung eines solchen komplexen Netzes sehr aufwändig.
Es zeigt sich, dass hier in der Regel Kompromisse gemacht werden
müssen.
Aus ihrem theoretischen Modell leiten Turtle und Croft (1991)
[->]
ein
weiter vereinfachtes Modell her, das in dem Retrieval-System INQUERY
implementiert wurde. Dazu
- verzichten sie auf die Textrepräsentationsschicht,
- leiten die Konzepte unmittelbar aus den Termen, die in den
Dokumenten vorkommen, her,
- verzichten auf die Anfrageschicht im Anfragenetz,
- verwenden anstelle der Wahrscheinlichkeiten allgemeinere Werte,
die aus einem IDF-Maß und anderen Häufigkeitsmaßen der
Terme gewonnen werden, und
- ersetzen die individuellen Funktionen in den Knoten durch eine
allgemeine Funktion, die in allen Knoten gleich
ist. Dabei gehen sie von einer
Unabhängigkeitsannahme bei der Berechnung der
Aktivierungswerte der Knoten aus.
Dadurch kann das System mit Hilfe einer
invertierten
Liste mit Wahrscheinlichkeitswerten implementiert werden
und ist trotz des zunächst komplexen Ansatzes
in der Lage, sehr große Dokumentensammlungen
zu verwalten. Es reduziert sich allerdings auch im Wesentlichen auf ein
gewichtetes Vektorraummodell. Über diese Struktur hinaus soll auch die
Integration von Abhängigkeiten zwischen Dokumenten und zwischen
Termen möglich sein - wie das allerdings realisiert wurde, ist aus
dem Text von 1991 nicht ersichtlich.
Zur Berechnung der Ähnlichkeiten zwischen einer Anfrage und einem
Dokument verwenden Turtle und Croft in ihrem Modell von 1991
verschiedene Formeln für die Wahrscheinlichkeit
eines einzelnen Knotens, die sich teilweise
als eine probabilistische Form des booleschen Retrieval interpretieren
lassen. Seien
wi,1,...,wi,r
die Werte der Knoten, die eine Verbindung zu einem Knoten
k
haben, dann lassen sich einige der Formeln so schreiben:
|
wor=1-(1-wi,1)
·...·(1-wi,r)
|
sowie
| ws= |
| (k1wi,1+
k2wi,2+...krwi,r)
kq |
 |
| k1+...+kr |
|
wobei leider sowohl die Bedeutung der Koeffizienten
k1,...kr
und des Werts
kq
als auch die probabilistische Interpretation in
Turtle und Croft (1991) unklar bleiben. Aufbauend auf der Formel (169
) für einen einzelnen Knoten berechnen Turtle
und Croft die Ähnlichkeit bei mehreren Query-Termen durch
| s |
(wi,q) |
= |
| wi · q |
|
| q · q |
|
wobei
q
ein Query-Vektor ist, der nur die Werte 0
und 1 enthält. Eine Besonderheit des Ansatzes ist, dass die
Gewichte der Terme im Dokumentvektor
wi
mit einem
Default-Wert d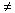 0
vorbelegt werden.
Das heißt, das Gewicht eines Terms, der in einem Dokument nicht auftritt, wird nicht
auf 0 gesetzt, sondern auf einen Wert wie
d=0,4
.
Die Gewichte werden entsprechend berechnet, z.B. nach der Formel 0
vorbelegt werden.
Das heißt, das Gewicht eines Terms, der in einem Dokument nicht auftritt, wird nicht
auf 0 gesetzt, sondern auf einen Wert wie
d=0,4
.
Die Gewichte werden entsprechend berechnet, z.B. nach der Formel
| wi,k=d+ |
| h(i,k) |
|
| h(k) |
|
oder verfeinerten Versionen davon. Im Falle der oben
verwendeten Ähnlichkeitsfunktion kann man aber die
Dokumentvektoren in einen konstanten Vektor,
der nur aus den Einträgen
d
besteht, und einen vom Dokument und dem
Term abhängigen Teil
wi~
aufspalten. Der konstante Vektor
trägt zu allen Ähnlichkeitswerten nur in Abhängigkeit zur
Zahl der Terme in der Anfrage bei:
| s |
(wi,q) |
= |
| (d+wi~)
·q |
|
| q · q |
|
= |
| d · q |
|
| q · q |
|
+ |
| wi~·q |
|
| q ·q |
|
Sein Beitrag ist also von den Dokumenten unabhängig
und liefert lediglich einen "Ähnlichkeitssockel".
Anders ist das bei dem von der AND-Verknüpfung abgeleiteten
Ähnlichkeitsmaß: |
| s(wi,q)= |
|
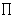 |
| qk=1 |
|
wi,k |
Hier führt ein einziges Gewicht mit dem Wert 0
dazu, dass die gesamte Ähnlichkeit gleich 0 ist, was ja auch dem
booleschen AND entspricht.
|

 Abbildung 78: Inferenznetz für das Information Retrieval nach Turtle und Croft
Abbildung 78: Inferenznetz für das Information Retrieval nach Turtle und Croft