3.5.6: Gewichtungsmethoden Lernen
In Abschnitt 1.3.6.3
über die
Gewichtung von Termen im Dokumentvektor wurden lokale Einflussfaktoren
wie der Dokumentteil (Titel, Abstract) genannt, die benutzt werden
können, um Terme oder Attribute eines Dokuments für die
Darstellung im Vektorraummodell zu gewichten. Dabei war allerdings nicht
näher beschrieben worden, wie die Gewichtung ermittelt werden soll.
Dazu kann man z.B. induktive Lernmethoden verwenden.
Als Beispiel soll hier der so genannte
Darmstädter Indexierungsansatz (Darmstadt Indexing
Approach)
DIA erwähnt werden. Dort wurde
zusätzlich zum Auftreten die Art und Weise, wie ein
Term in einem Dokument auftritt,
erhoben.
Das kann z.B. die Häufigkeit des Auftretens im Dokument,
die Stelle des Auftretens (z.B. Titel, Stichwortverzeichnis oder Abstract) oder eine
Kombination solcher Angaben sein. Allgemein kann man die
Auftrittsform
(bei Fuhr und Buckley (1991) [->]
relevance description genannt)
als ein Attribut
Ai:D->Ri
formulieren, in das auch weitere Informationen über
den Term und das Dokument einfließen können, wie die Länge des Dokuments oder
die Häufigkeit des Terms in der Dokumentensammlung. Die meisten Eigenschaften eines Terms, die
dabei verwendet werden, hängen nicht von seiner Bedeutung ab, sondern können allgemein erhoben
werden. Werden nur solche Eigenschaften verwendet, kann man die Auftrittsform als Funktion des
Dokuments
d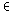 D
und des Terms
tiT
auffassen, also als eine Abbildung D
und des Terms
tiT
auffassen, also als eine Abbildung
|
x:D×T-> |
|
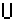 |
| iI
|
|
Ri |
mit
x(d,ti)=Ai
(d)
, wobei aber
Ri=Rj:=R 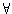 i,j
{1,...,n}
gilt. Das heißt, man abstrahiert von den einzelnen Termen und erhebt
nur die Auftrittsform. Die verschiedenen Ausprägungen der Auftrittsform,
also die Werte aus
R
, können dann als Basis für die Gewichtung
des Terms im Dokumentvektor verwendet werden. i,j
{1,...,n}
gilt. Das heißt, man abstrahiert von den einzelnen Termen und erhebt
nur die Auftrittsform. Die verschiedenen Ausprägungen der Auftrittsform,
also die Werte aus
R
, können dann als Basis für die Gewichtung
des Terms im Dokumentvektor verwendet werden.
Weiter kann man die verschiedenen Bedingungen, die in der Beschreibung der Auftrittsform
verwendet werden, auch als separate Attribute auffassen, die dann z.B.
die Häufigkeit, mit der ein Term im Dokument auftritt, den Ort, an dem er auftritt, oder
die Anzahl der Dokumente in der Sammlung, in denen
er auftritt, einzeln beschreiben. Sie können bei der Berechnung der Gewichtung eines
Terms in unterschiedlichem Maße beitragen.
Der jeweilige Einfluss dieser Auftrittsformen kann mit
verschiedenen Methoden bestimmt werden. Wenn Trainingsdaten zur Verfügung stehen, können
z.B. Machine-Learning-Verfahren verwendet werden.
Dadurch, dass Auftrittsformen unabhängig von den
tatsächlichen Termen betrachtet werden, verringert sich die
Anzahl der im Machine-Learning-Ansatz zu bearbeitenden
Attribute. Außerdem erhöht sich die Anzahl der Trainingsbeispiele, da jeder Term,
der in einer Anfrage und einem für die Anfrage bewerteten Dokument vorkommt, ein
Trainingsbeispiel erzeugt. Beispiele für Attribute sind in
Abbildung 97
angegeben. (Nach Fuhr und Buckley (1991)
[->]
.)
Im Rahmen des Darmstädter Ansatzes
wurden verschiedene Verfahren zur Bestimmung von
Indexierungsfunktionen - also Funktionen, nach denen
die verschiedenen Auftrittsformen gewichtet werden - verwendet.
Dazu gehörten der ID3-Algorithmus, ein Maximum-Spanning-Tree-Ansatz (der
paarweise Abhängigkeiten unter den Komponenten zulässt), ein
Ansatz, der auf der logistischen Regression beruht, und eine Methode der
kleinsten Fehlerquadrate auf einem Raum von
Polynomen. Dabei wurden (nach Fuhr und Buckley, 1991
[->]
) gute Ergebnisse erzielt,
wenn ausreichend Relevanzdaten zur Verfügung standen.
Stehen stark strukturierte Dokumente - wie
SGML- oder XML-Dokumente - zur Verfügung, können Auftrittsformen
wesentlich flexibler definiert werden als bei schwach strukturierten
Dokumenten. Wieweit dadurch die Retrieval-Ergebnisse verbessert werden können,
ist allerdings noch offen. Erste Ansätze werden in Abschnitt 4.1.4
beschrieben.
|

 Abbildung 97: Einflussfaktoren von Auftrittsformen nach Fuhr und Buckley
Abbildung 97: Einflussfaktoren von Auftrittsformen nach Fuhr und Buckley